MMBench

MMBench
全方位的多模态大模型能力评测体系

MMBench是什么
MMBench是多模态基准测试,由上海人工智能实验室、南洋理工大学、香港中文大学、新加坡国立大学和浙江大学的研究人员联合推出。MMBench推出一个综合评估流程,从感知到认知能力逐级细分评估,覆盖20项细粒度能力,从互联网与权威基准数据集采集约3000道单项选择题。打破常规一问一答基于规则匹配提取选项进行评测,循环打乱选项验证输出结果的一致性,基于ChatGPT精准匹配模型回复至选项。MMBench涵盖多种任务类型,如视觉问答、图像描述生成等,基于综合多维度指标,为模型提供全面的性能评估。MMBench 的排行榜展示不同模型在这些任务上的表现,帮助研究者和开发者了解当前多模态技术的发展水平,推动相关领域的技术进步。
MMBench主要功能
- 细粒度能力评估:将多模态能力细分为多个维度(如感知、推理等),针对每个维度设计相关问题,全面评估模型的细粒度能力。
- 大规模多模态数据集:提供约 3000 个多项选择题,覆盖 20 种能力维度,支持模型在多种场景下的性能测试。
- 创新评估策略:采用“循环评估”策略,用多次循环推理测试模型的稳定性,减少噪声影响,提供更可靠的评估结果。
- 多语言支持:提供英文和中文版本的数据集,支持对模型在不同语言环境下的能力评估。
- 数据可视化:支持数据样本的可视化,帮助用户更好地理解数据结构和内容。
- 官方评估工具:提供 VLMEvalKit,支持对多模态模型的标准化评估,并可用于提交测试结果获取准确率。
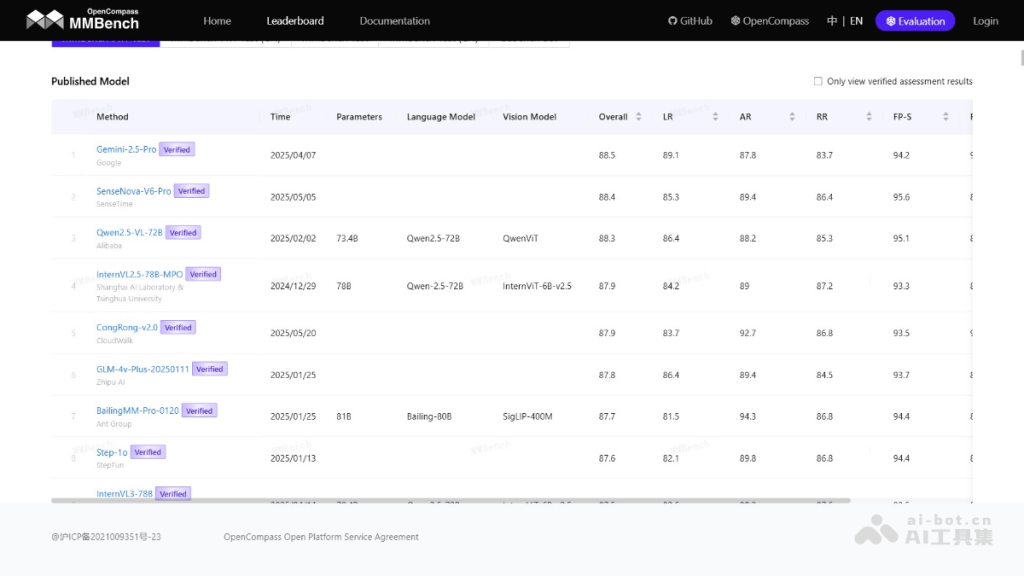
- 基准测试与排行榜:排行榜展示不同模型在 MMBench 数据集上的性能表现,为研究者提供参考。
- 评估模型性能:用 VLMEvalKit 对模型的预测结果进行评估。评估工具根据 MMBench 的标准计算准确率等指标。
- 提交测试结果:
- 在 MMBench 领先榜上提交测试结果,按照以下步骤操作:
- 使用测试集数据进行推理,生成预测结果文件(如
llava_v1.5_7b/MMBench_TEST_EN.xlsx)。 - 登录 MMBench 领先榜上传预测结果文件。
- 领先榜将自动计算并展示模型在各个能力维度上的性能表现。
- 使用测试集数据进行推理,生成预测结果文件(如
- 在 MMBench 领先榜上提交测试结果,按照以下步骤操作:
MMBench的应用场景
- 模型性能评估:MMBench 提供全面的多模态基准测试平台,能对视觉语言模型在不同任务和能力维度上的表现进行细粒度评估,帮助研究者和开发者清晰了解模型的强项和弱项,为模型优化提供方向。
- 学术研究支持:研究人员用 MMBench 数据集进行新模型的开发和验证,推动多模态技术的前沿研究。
- 工业应用开发:在工业领域,企业评估和选择适合其产品的多模态模型,确保所采用的模型在实际应用场景中具备足够的性能和稳定性,提高产品的市场竞争力。
- 教育与培训:作为教学资源,帮助学生和研究人员更好地理解多模态模型的评估方法和应用场景,基于实践项目和课程练习提升对多模态技术的理解和应用能力。
- 跨领域应用:MMBench 的多模态数据集涵盖多个领域,如文化、科学、医疗等,例如 CCBench(中国文化相关基准测试)能评估模型在特定文化领域的表现,推动文化研究和跨文化交流。